
1.前言
近期要用excel统计学生成绩与统计,但网上找不到学生成绩的数据所以就用python生成了,记录一下。
2.生成姓名和学号,科目
from openpyxl import Workbook, load_workbook
from faker import Faker
#xlsx表格地址
path = r"C:\Users\clover\Desktop\1.xlsx"
# 创建一个 workbook
wb = load_workbook(filename=path)
# # 获取被激活的 worksheet
ws = wb['Sheet1']
# 设置生成姓名的地区
fake = Faker("zh_CN")
# 设置单元格内容
ws['A1'] = "学号"
ws['B1'] = "姓名"
ws['C1'] = "语文"
ws['D1'] = "数学"
ws['E1'] = "英语"
ws['F1'] = "物理"
ws['G1'] = "地理"
ws['H1'] = "化学"
ws['I1'] = "生物"
ws['J1'] = "政治"
ws['K1'] = "历史"
# 生成学号
sjs = 0
# 生成的个数
for i in range(2,52):
ws[f"A{i}"] = "2021D001"+ "%02d"%(sjs)
sjs += 1
# 生成姓名
for k in range(2,52):
ws[f"B{k}"] = fake.name()
这里要安装2个库
pip install openpyxl
pip install faker
3.生成分数
一开始是用自带的random生成的但发现一个问题,生成的数不符合真实的的情况,生成的数据全部在0-59分这个区间,后面查了资料发现学生成绩是呈正太分布的,既然是正太分布那就用numpy这个库生成正太分布的随机数。下面是代码。
pip install numpy
import numpy as np
# 生成正太分布的0-100的随机整数
def get_random():
mean = 75 # 正态分布的均值
std = 11 # 正态分布的标准差
size = 50 # 生成随机数的个数
# 生成正态分布的随机数
random_nums = np.random.normal(mean, std, size)
# 将随机数限制在0到100之间
random_nums = np.clip(random_nums, 0, 100)
# 将随机数转换为整数
integer_nums = random_nums.astype(int)
return integer_nums
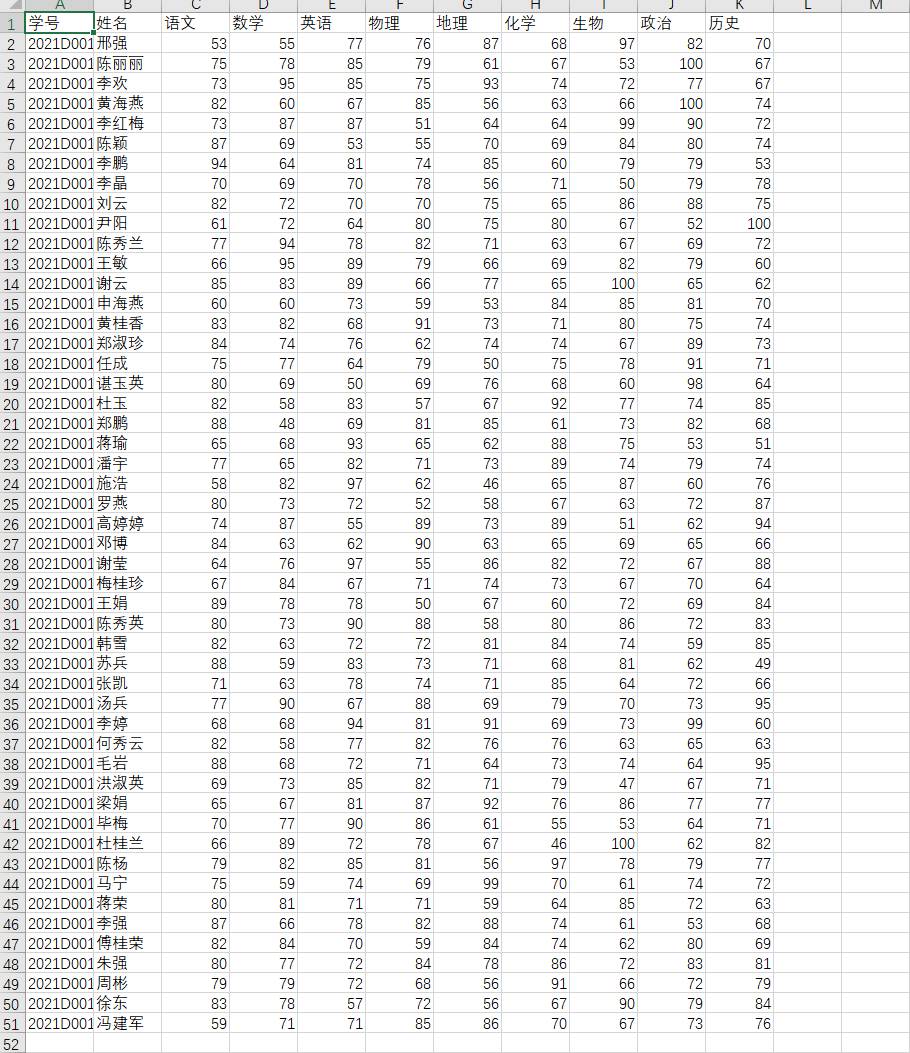
4.全部代码
from openpyxl import Workbook, load_workbook
import random
import datetime
from faker import Faker
import numpy as np
# 生成正太分布的0-100的随机整数
def get_random():
mean = 75 # 正态分布的均值
std = 11 # 正态分布的标准差
size = 50 # 生成随机数的个数
# 生成正态分布的随机数
random_nums = np.random.normal(mean, std, size)
# 将随机数限制在0到100之间
random_nums = np.clip(random_nums, 0, 100)
# 将随机数转换为整数
integer_nums = random_nums.astype(int)
return integer_nums
#xlsx表格地址
path = r"C:\Users\clover\Desktop\1.xlsx"
# 创建一个 workbook
wb = load_workbook(filename=path)
# # 获取被激活的 worksheet
ws = wb['Sheet1']
# 设置生成姓名的地区
fake = Faker("zh_CN")
# 设置单元格内容
ws['A1'] = "学号"
ws['B1'] = "姓名"
ws['C1'] = "语文"
ws['D1'] = "数学"
ws['E1'] = "英语"
ws['F1'] = "物理"
ws['G1'] = "地理"
ws['H1'] = "化学"
ws['I1'] = "生物"
ws['J1'] = "政治"
ws['K1'] = "历史"
# 生成学号
sjs = 0
# 生成的个数
for i in range(2,52):
ws[f"A{i}"] = "2021D001"+ "%02d"%(sjs)
sjs += 1
# 生成姓名
for k in range(2,52):
ws[f"B{k}"] = fake.name()
l = ["C","D","E","F","G","H","I","J","K"]
for z in l:
a = 2
data = get_random()
for i in data:
ws[f"{z}{a}"] = i
a += 1
# # 设置一行内容
# # 保存 Excel 文件
wb.save(r"C:\Users\clover\Desktop\2.xlsx")


默认评论
Halo系统提供的评论